Την έκδοση AlphaGo Zero ανακοίνωσε η DeepMind, θυγατρική της Google για την τεχνητή νοημοσύνη (AI). Χαρακτηριστικό της τελευταίας έκδοσης όμως είναι ότι ενώ οι προηγούμενες μάθαιναν Go –επιτραπέζιο παιχνίδι στρατηγικής- από παρτίδες ερασιτεχνών ή επαγγελματιών παιχτών, το AlphaGo Zero έμαθε μόνο του με αντίπαλο τον εαυτό του. Πλέον, το AlphaGo Zero νίκησε τους προκάτοχούς του […]
Την έκδοση AlphaGo Zero ανακοίνωσε η DeepMind, θυγατρική της Google για την τεχνητή νοημοσύνη (AI). Χαρακτηριστικό της τελευταίας έκδοσης όμως είναι ότι ενώ οι προηγούμενες μάθαιναν Go –επιτραπέζιο παιχνίδι στρατηγικής- από παρτίδες ερασιτεχνών ή επαγγελματιών παιχτών, το AlphaGo Zero έμαθε μόνο του με αντίπαλο τον εαυτό του.
Πλέον, το AlphaGo Zero νίκησε τους προκάτοχούς του και αποτελεί τον ισχυρότερο παίκτη Go στην ιστορία.
Εν αρχή νίκησε την προηγούμενη έκδοση με 100-0 και εν συνεχεία την έκδοση Master με 89-11. Να σημειωθεί ότι η έκδοση Master είχε νικήσει τον καλύτερο παίκτη Go παγκοσμίως, τον Ke Jie τον Μάιο.
Η νίκη έναντι της προηγούμενης έκδοσης του Go επήλθε ύστερα από εκπαίδευση τριών ημερών, ενώ η νίκη εναντίον της Master έκδοσης χρειάστηκε 40 μέρες εκπαίδευσης.
Σύμφωνα με την εταιρεία, αυτό που βοήθησε κι αποτέλεσε παράγοντα απελευθέρωσης ήταν ότι αφαιρέθηκαν οι περιορισμοί που επιβάλει η ανθρώπινη γνώση.
Η εταιρεία αναφέρει ότι αν εφαρμοστούν παρόμοιες τεχνικές σε άλλα προβλήματα όπως η αναδίπλωση πρωτεϊνών, η μείωση της κατανάλωσης ενέργειας ή η αναζήτηση επαναστατικών νέων υλικών, οι ανακαλύψεις που θα προκύψουν, θα μπορούσαν να αλλάξουν την κοινωνία προς μια θετική κατεύθυνση.
Το κίνητρο και να μου το θυμηθείτε για να κερδίσει κανείς αυτή την τεχνητή νοημοσύνη είναι να συμπεριφέρεσαι απρόβλεπτα. Ότι έκανες να μην το κάνεις πια και ας είναι εναντίον του όφελούς σου. Σε όλους αυτούς τους αλγορίθμους η βελτιστοποίηση είναι βαθιά ριζωμένη και δεν μπορούν να καταλάβουν από μπλόφα, ρίσκο ή πιθανότητες
Αν το ρωτήσεις ποιος πιστεύει πως θα κερδίσει δε θα μπορεί να σου απαντήσει γιατί δεν ξέρει να πιστεύει. Τον κυριούλη λυπάμαι που χαίρεται τόσο λες και γέννησε η γυναίκα του παιδί
Μπορεί να θέλει πολύ δρόμο ακόμη για να φθάσει στο επίπεδο της Blue Origin ή της SpaceX, αλλά η βρετανική startup επιχείρηση Orbex νιώθει αρκετά σίγουρη για να προχωρήσει στο δεύτερο στάδιο κατασκευής του βασικού πυραύλου της.
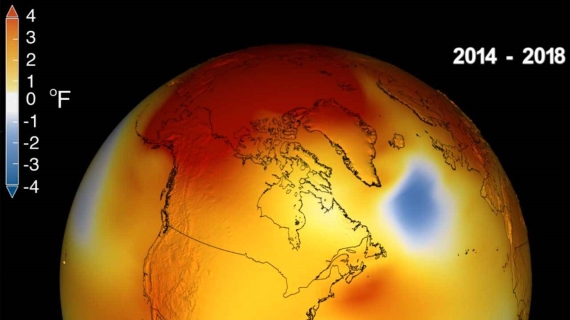
Αν περάσατε πολύ χρόνο έξω το περασμένο καλοκαίρι και είχατε την εντύπωση ότι δεν ήταν και τόσο ζεστό όπως τα προηγούμενα χρόνια, είχατε δίκιο. Η NASA και η NOAA ανακοίνωσαν ότι οι παγκόσμιες επιφανειακές θερμοκρασίες το 2018 ήταν οι τέταρτες θερμότερες από το 1880. Αυτό σημαίνει ότι το 2018 ήταν το τέταρτο καυτότερο έτος που […]
Η HMD ετοιμάζει ένα νέο χαρακτηριστικό Nokia, μια συσκευή Series 30+. Έχει ωραίο εργονομικό σχήμα, επιπλέον είναι πάρα πολύ ελαφρύ (μόλις 83.6g) και με υπερβολικά μεγάλη μπαταρία 1.020mAh για την κατηγορία του. Με τέτοια μπαταρία έχει τη δυνατότητα να διαρκεί τόσο πολύ που θα ξεχνάτε να το φορτίσετε.
Η Google φέρνει επιτέλους μερικές από τις πιο πρακτικές λειτουργίες του Waze στο Google Maps, με την πιο αξιοσημείωτη να είναι οι προειδοποιήσεις για τους κρυμμένους μετρητές ταχύτητας της Τροχαίας.




Το κίνητρο και να μου το θυμηθείτε για να κερδίσει κανείς αυτή την τεχνητή νοημοσύνη είναι να συμπεριφέρεσαι απρόβλεπτα. Ότι έκανες να μην το κάνεις πια και ας είναι εναντίον του όφελούς σου. Σε όλους αυτούς τους αλγορίθμους η βελτιστοποίηση είναι βαθιά ριζωμένη και δεν μπορούν να καταλάβουν από μπλόφα, ρίσκο ή πιθανότητες
Αν το ρωτήσεις ποιος πιστεύει πως θα κερδίσει δε θα μπορεί να σου απαντήσει γιατί δεν ξέρει να πιστεύει. Τον κυριούλη λυπάμαι που χαίρεται τόσο λες και γέννησε η γυναίκα του παιδί